Punti chiave
Huawei Mate 10 Pro è un grande smartphone. L’azienda doveva confermare la sua competitività a livello mondiale e ci è riuscita benissimo, tirando fuori un prodotto di altissimo livello.
Saremo subito chiari, e vi diciamo subito a chi potrà piacere e a chi no. Piacerà moltissimo a chi vuole un telefono tuttofare, intelligente, che vuole divertirsi con millemila applicazioni che svolgono le funzioni più impensate. Sarà veramente un ottimo prodotto per tutti coloro che vogliono delle alte prestazioni e hanno un approccio molto pratico allo smartphone, che deve fare quello che gli serve, senza prestare molta attenzione ai dettagli tecnici.
Non piacerà ad una parte dei puristi della tecnologia: c’è chi scarta un telefono a priori perchè non ha il jack da 3.5 mm per le cuffie e c’è chi è estremamente intransigente sulla possibilità di aggiungere memoria tramite schedine MicroSD. A costoro Huawei Mate 10 Pro non dovrebbe piacere. E potrebbe scontentare anche chi ama alla follia l’ambiente Android, ne è un ammiratore e sostenitore, perche Mate 10 Pro ne modifica profondamente l’aspetto e le funzionalità proponendo una sua versione.
Detto questo, Huawei Mate 10 Pro offre una quantità di cose veramente ampia e possiamo dire che ha posto due nuovi standard nel mercato: il primo prodotto ad integrare una intelligenza artificiale supportata da un processore “neuronale” che vuole imitare il cervello umano, e la durata della batteria, piuttosto strabiliante, unita all’esclusiva della ricarica rapida Quick Charge.
Huawei Mate 10 Pro. Design
Huawei Mate 10 Pro è composto da un vetro Corning Gorilla Glass 5 che racchiude un anima di metallo. Questo lo rende molto bello e luccicante, solido in mano, e con dei simpatici giochi di luce sul retro, anche se sotto questo aspetto non arriva alla magnificenza dei riflessi di Honor 10.
Appena sbucato dalla scatola, Huawei Mate 10 Pro è dotato di una pellicola protettiva sullo schermo e di una cover in silicone, che lo aiutano a sembrare ancora più resistente e soprattutto a non scivolare dalle mani, problema che condividono un po’ tutti i dispositivi realizzati in vetro. Ha anche il fattore di protezione IP67, che significa che ha una buona resistenza alla polvere e anche all’acqua, nel senso che se lo bagniamo con la doccia o lo immergiamo nel lavandino sopravvive, anche se è meglio tirarlo fuori dopo qualche minuto.
Nei video dove si divertono a picchiare gli smartphone per vedere quanto sono resistenti, hanno provato a farlo cadere dalla tasca e non è successo nulla di particolare per un paio di volte. Se casca da 1.5 metri e sfortunatamente viene colpito di angolo, questo si sbreccia un po’ anche se rimane perfettamente funzionante. Stessa cosa a 2 metri di altezza, e il display potrebbe scheggiarsi.
In generale è abbastanza resistente, dunque, anche se nella scala generale di forza è a livello medio, ovvero esistono prodotti molto più forti.
E’ disponibile nei colori Mocha Brown, Midnight Blue, Titanium Gray e Pink Gold.
Sul retro troviamo i due sensori della fotocamera. Huawei non li ha riuniti in un unico blocco come avviene di solito, ma li ha resi indipendenti l’uno dall’altro, ognuno nel suo buchetto, che sporgono leggerissimamente di qualche millimetro. Il sensore per il riconoscimento delle impronte digitali per lo sblocco del dispositivo è di una velocità supersonica: basta anche accennare di appoggiare il dito perchè compaia il display acceso.
Due speaker, uno in basso e uno in alto, sono posizionati strategicamente nel tentativo di creare una sorta di stereo, che come vedremo nella sezione apposita, è un obiettivo quasi raggiunto.
A destra troviamo i classici tasti di accensione/spegnimento e per la regolazione del volume, mentre a sinistra l’entrata per la Nano SIM. In alto troviamo anche il sensore IR per utilizzare il Huawei Mate 10 Pro come un telecomando.
Tutto sommato, il design generale è molto buono.













Display
Il display da 6 pollici pieni, è molto grande. Molto grande. Ha un rapporto di 18:9, ovvero è un rettangolo perfetto, e l’80,9% del prodotto è coperto dall’area dello schermo. E’ una percentuale piuttosto alta, e infatti Huawei ha dovuto persino scrivere in basso il suo marchio per ricordare chi sia il costruttore del dispositivo, tanto lo schermo è grande.
A livello tecnico ci troviamo di fronte ad un OLED +HDR10 in Wide Full HD. Ovvero siamo di fronte ad una eccellente qualità del display. E’ piuttosto luminoso, perchè con 449 nit di lucentezza è leggermente superiore ai suoi concorrenti. Per cui possiamo considerarlo un ottimo schermo: messo in comparazione con gli altri possiamo definirlo certamente migliore di prodotti come il Google Pixel 2 e LG V30, certamente. Appena leggermente inferiore al Galaxy Note 8 e sotto Xperia XZ Premium.
Per cui il display si colloca pienamente a metà della scala dei valori sul mercato.
All’accensione il display ha la regolazione intelligente della luminosità. Se provate ad andare alla luce e poi più al buio, lo schermo si regola da solo. Ma in generale è impostato con una luminosità troppo bassa e lo abbiamo subito disattivato. La modalità standard è Normal con una piccola accelerazione sui colori, che lo pone di default un pochetto più vivace del Galaxy Note 8. Possiamo però scegliere anche la sola modalità Vivid che esaspera i colori per chi vuole uno schermo “cattivo”.
Hardware
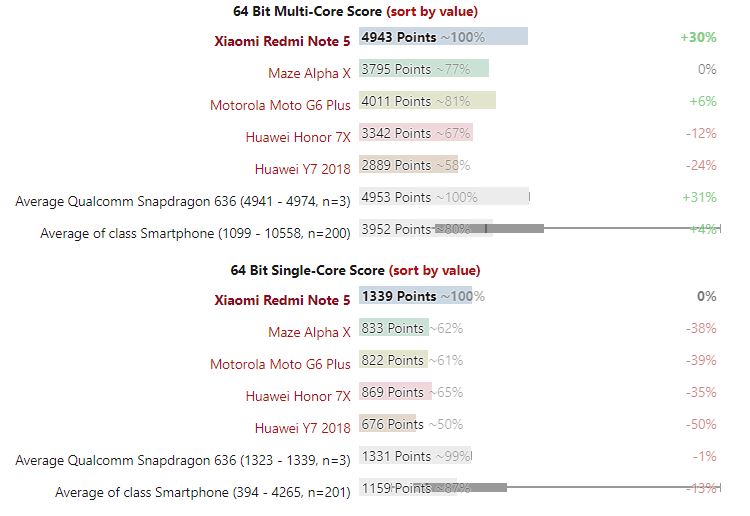
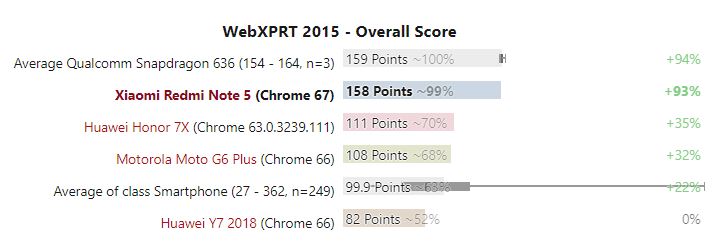
Huawei Mate 10 Pro arriva con il processore Kirin 970 e 6GB di RAM. Per cui la dotazione di partenza è assolutamente ottima. Utilizzato sotto stress, non ha mai mostrato segni di cedimento, nemmeno con tante tante applicazioni aperte, internet che gira di continuo o musica in background. Per darvi una idea, converte un video in 4K in uno in 1080p della durata di un paio di minuti in 58 secondi, superando il più diretto concorrente, il Galaxy Note 8 che ha impiegato 1.2 minuti.
Osservando i benchmark, Huawei non può che essere soddisfatta. Sia nelle comparazioni single core che multi core del processore, Huawei Mate 10 Pro è sopra a Google Pixel 2, e al Galaxy Note 8. Per cui nella velocità pura (come per le auto il rettilineo) la vittoria è assicurata. E’ superiore anche nelle prestazioni relative alla grafica 3D, anche se in questo settore il divario è più basso rispetto alla concorrenza.
Una elemento di cui parlare è certamente la NPU. Si tratta di un processore aggiuntivo, chiamato “Neuronale“, che vuole imitare il ragionamento umano. In realtà è sostanzialmente quella unità di calcolo preposta alle performance che dovrebbero anticipare i nostri desideri e le nostre mosse. Se dobbiamo dire la verità: a livello pratico non vediamo una gigantesca differenza con la concorrenza. Ovvero non troviamo una forma di intelligenza aliena che pensa meglio e prima di noi. Dobbiamo però riconoscere la volontà di Huawei di sdoganare una tecnologia, di esprimere un pensiero nuovo che non possiamo non apprezzare.
Certamente, come abbiamo detto all’inizio della recensione, questa intelligenza neuronale è un nuovo standard del mercato con cui i concorrenti si dovranno misurare.
Sistema operativo
Huawei Mate 10 Pro ha un bell‘Android 8.0 Oreo a cui si aggiunge una interfaccia grafica e operativa propria di Huawei che è EMUI 8.0
Questo allontana di fatto Huawei Mate 10 Pro dall’ambiente Android, e ne propone una versione differente e personalizzata. Cosa ci dà tutto questo? dire un mare di funzioni è poco.
Innanzitutto l’aggiornamento costante e l’installazione rapida di patch di sicurezza. Inoltre, una barra delle notifiche particolarmente intelligente, dove ogni messaggio è ben diviso dagli altri. Addirittura, questo lo abbiamo gradito molto, possiamo cliccare su una linguetta e leggere l’inizio di una mail o di un messaggio whatsapp già dentro la barra delle notifiche. Android Oreo offre la funzione “Picture in Picture“: per spiegarla in pratica, la possibilità di vedere un filmato di YouTube più piccolino e flottante nel frattempo che usiamo altre applicazioni.
La barretta in basso, quella con i tre tasti per andare indietro, vedere le app aperte o ritornare alla Home Page può essere personalizzata. Addirittura anzichè quella possiamo attivare un bottone fluttuante con tutte le funzioni. Certamente è comodo, veloce e funzionale, anche se a volte è un po’ fastidioso avercelo sempre in mezzo durante l’uso delle app. Diciamo che è una funzione avanzata che corre sul filo del fastidio.
Huawei Mate 10 Pro propone anche la funzione”Touch Disable“, cioè per evitare di riattivare lo schermo per caso, dobbiamo accuratamente evitare di coprire la parte superiore con la mano quando digitiamo il PIN. E’ un esempio della volontà Huawei di capire le nostre intenzioni. In questo caso possiamo dirvi, colmi di fierezza, che è fastidiosissima.
Abbiamo anche la funzione multifinestra, abbastanza utile, e registrazione di video dei nostri passaggi sullo schermo, quest’ultima molto gradevole. Una figata pazzesca è la modalità “Private Space“. Esempio pratico: avete provato quel brivido profondo quando vostra madre o la vostra ragazza vi chiedono lo smartphone, a magari su whatsapp vi hanno inoltrato chissà cosa? si, ammettiamolo, lo abbiamo provato tutti.
Ora, se andiamo in “Impostazioni” e selezioniamo l’opzione “Spazio Privato“, possiamo registrare un PIN, che deve essere diverso da quello già impostato, e una seconda impronta digitale, anch’essa differente da quella già in uso.
Ad esempio, l’indice della mano destra e quello della mano sinistra. Se spegniamo lo schermo, e sblocchiamo con il dito destro, tutto regolare. Se spegniamo e sblocchiamo con l’indice sinistro, comprare una versione alternativa dello stesso smartphone, completamente separata. Insomma, due smartphone che coesistono sullo stesso dispositivo. Uno personale e uno per il lavoro, o uno regolare e uno “santo” da mostrare ai conoscenti. Fantastico!
Simile App Pair, che consente di gestire due account diversi di una app, tipo Facebook. Anch’essa ottima anche se un po’ lenta.
Camera principale
Huawei Mate 10 Pro ha due sensori: uno da 12MP RGB, dedicato ai colori, e uno da 20MP monocromatico per il bianco e nero. Abbiamo uno stabilizzatore ottico molto potente e una apertura di f1/6 che è la più ampia che esista nella sua fascia, segno che Huawei ha ancora una volta voluto “tirare” la barra in avanti.
Come si comporta? in condizioni di luce perfettamente normali le foto sono belle. Ma in comparazione con i suoi avversari, fa meno bene di tutti loro. Certo, il focus e i colori sono eccellenti, ma non arriva ad avere quella ricchezza di particolari. Dobbiamo dirlo. Inoltre a volte soffre un pochino di sovraesposizione quando abbiamo molta luce, il che lo colloca sotto alla potenza di Google Pixel 2, ad esempio.
In compenso abbiamo una miriade di opzioni per mettere a fuoco: da Laser, per identificare un punto preciso, a Phase per spazi ampi, passando per Depth, quando abbiamo molta profondità. Ma ce ne sono molti ancora.
In condizioni di poca luce invece Huawei Mate 10 Pro si comporta davvero molto bene: riesce a gestire quella poca luminosità a sua disposizione e a fare degli ottimi scatti. Viene superato di pochissimo da Samsung Note 8.





Huawei Mate 10 Pro ha puntato moltissimo sul focus: possiamo ingrandire un oggetto fino a 6X, per cui sotto questo aspetto non abbiamo nulla da temere, anche perchè il focus è supportato, di nuovo, da quella forma di intelligenza artificiale che costituisce il “quid” del prodotto. In realtà siamo aiutati, certo, ma a volte con lo zoom la foto si sgrana e si pixellizza un po’.
Abbiamo comunque molte altre funzioni interessanti: parliamo della modalità per il ritratto di soggetti multipli che cerca un equilibrio nella messa a fuoco, un angolo di visuale veramente ampio che ci consente di riprendere appieno grandi paesaggi e un refocus ottimo, ovvero possiamo fare una foto focalizzandoci su un punto, e dopo averla scattata sceglierne un altro per avere più versioni di una immagine con punti di focalizzazione differenti.
Il Night Mode è abbastanza bello, e permette di collegare più frammenti per realizzare quelle foto dinamiche, quelle con le scie luminose che rappresentano gli oggetti in movimento, che fanno tanto figo.
Video
Possiamo registrare dai 1080p ai 4K. Buona qualità, bell’audio. La conversione in qualsiasi altro formato è rapida ed efficiente. Abbiamo notato una ottima velocità nel caricamento su YouTube. Nel complesso, soddisfatti.
Audio
Huawei Mate 10 Pro ha due speaker. Uno in basso e uno in alto che vogliono offrire una specie di stereo. Ci riesce? possiamo dire (quasi) di sì. Certamente il suono è molto bello e molto ricco. Sia negli alti che nei bassi si sente molto bene e i toni non gracchiano mai.
Se passiamo l’audio in cuffia, non possiamo farlo attraverso il mini jack da 3.5 perchè non c’è: e questo potrebbe fare inorridire molti. Il problema è che non c’è nemmeno l’adattatore da USB-C a jack 3.5 mm, quindi sostanzialmente le vecchie cuffiette ve le dovete proprio dimenticare. E questo è piuttosto frustrante.
L’unica alternativa sono le cuffie con l’USB-C già pronto o il collegamento tramite Bluetooth. In quest’ultima modalità, l’audio è veramente perfetto.
Camera Selfie
Per scattarci i selfie abbiamo un sensore da 8MP che ha il miglioramento dei volti incluso. Huawei Mate 10 Pro aumenta la luce, scurisce le ombre e crea un leggero effetto sfocato sullo sfondo per far risaltare il nostro volto.
Rete e chiamate
Molto bene. Esiste sia nella versione mono che Dual SIM con Nano SIM. Il passaggio tra un numero e l’altro è istantaneo e soddisfacente. Prende bene sia il WiFi che la connessione dati. Il bluetooth è 4.2, sarebbe stato meglio un 5, però è molto stabile e non ci ha mai dato problemi.
Memoria e dati
Huawei Mate 10 Pro ha due versioni. Quella minore da 64GB e la standard con ben 128GB. Qui va a preferenza: di norma tanta memoria basta per quasi tutti, ma esistono i “puristi” a cui non piace per nulla l’impossibilità di utilizzare le schedine per gestire e aumentare lo spazio a disposizione.
Batteria e durata
E qui un altro punto forte del prodotto. La batteria. E quando diciamo che è un punto forte, non diciamo che nella categoria è posizionato bene, e nemmeno in cima, ma affermiamo che Huawei Mate 10 Pro scrive un nuovo standard a cui gli altri devono arrivare.
Per la cronaca, appena uscì, il Mate 10 aveva una batteria che non durava fino al pomeriggio, per via di un errore nella gestione del processore. Poi la Huawei rilasciò un aggiornamento che cambiò radicalmente la situazione. Per cui si notate poca autonomia, assicuratevi di aver eseguito l’update del prodotto almeno la prima volta.
Detto ciò, siamo di fronte ad una batteria dalla straordinaria efficienza e durata. Una carica al 100% dura un giorno fino a tarda notte con un utilizzo intenso, e quasi due giorni se non state sempre incollati allo smartphone. Ad esempio: un video HD, con la massima brillantezza e il WiFi che riceve, consuma il 9% di batteria in 90 minuti. Galaxy S8 Plus ha consumato l’11%, LG V30 il 12% e iPhone 8 23%. In totale, con uso intenso, Huawei Mate 10 Pro dura 14 ore e 30 minuti. E’ davvero fantastico.
Ma non solo: Huawei ha sdoganato anche la tecnologia del Quick Charge. Una ricarica ultrarapida che si appoggia all’entrata USB-C per cui va da 0 al 50% in 30 minuti. Non possiamo che applaudire. Vogliamo trovare un difetto? Niente ricarica Wireless, sebbene la struttura del dispositivo in linea teorica lo permette.
Trucchi
Huawei Mate 10 Pro ha una quantità di applicazioni gigantesca. Se vogliamo trovare un bel trucco possiamo comunque citare la poco nota possibilità di collegare il dispositivo ad un monitor esterno come fosse un PC. EMUI Desktop è il nome della funzione. Dobbiamo solamente prendere un adattatore che da USB-C esca in HDMI e il gioco è fatto. Proviamo a collegare e il dispositivo fa tutto da solo.
Oddio, l’esperienza non è magnifica. Si vede che ci troviamo di fronte ad una interfaccia per smartphone adattata all’utilizzo desktop, quindi che si pensi di poter lavorare come fosse un terminale professionale. Però apprezziamo lo sforzo della casa madre di pensare anche a questo.
Prezzo e disponibilità
Rilasciato nell’ottobre del 2017, Huawei Mate 10 Pro è pienamente disponibile sul mercato al prezzo medio di €400.
Scheda tecnica
| LANCIO | Annuncio | Ottobre 2017 |
|---|---|---|
| Stato | Disponibile |
| CORPO | Dimensioni | 154.2 x 74.5 x 7.9 mm |
|---|---|---|
| Peso | 178 g | |
| Materiale | Fronte/retro vetro, corpo alluminio | |
| SIM | Singola SIM (Nano-SIM) o Dual SIM (Nano-SIM, dual stand-by) | |
| – IP67 resistente polvere/acqua (fino a 1m per 30 min) |
| DISPLAY | Tipo | AMOLED touchscreen capacitivo, 16M colori |
|---|---|---|
| Misure | 6.0 pollici, 92.9 cm2 (~80.9% screen-to-body ratio) | |
| Risoluzione | 1080 x 2160 pixel, 18:9 ratio (~402 ppi densità) | |
| Multitouch | Si | |
| Protezione | Corning Gorilla Glass 5 | |
| – HDR10 – EMUI 8.0 |
| PIATTAFORMA | OS | Android 8.0 (Oreo) |
|---|---|---|
| Chipset | HiSilicon Kirin 970 | |
| CPU | Octa-core (4×2.4 GHz Cortex-A73 & 4×1.8 GHz Cortex-A53) | |
| GPU | Mali-G72 MP12 |
| MEMORIA | Card slot | No |
|---|---|---|
| Interna | 128 GB, 6 GB RAM o 64 GB, 4 GB RAM |
| FOTOCAMERA | Doppia | 12 MP, f/1.6, 27mm, 1/2.9″, 1.25µm, OIS, PDAF & laser AF 20 MP B/W, f/1.6, 27mm, 2x zoom, OIS, PDAF & laser AF |
|---|---|---|
| Funzioni | Lenti Leica, dual-LED dual-tone flash, panorama, HDR | |
| Video | 2160p@30fps, 1080p@30/60fps |
| SELFIE CAMERA | Singola | 8 MP, f/2.0, 26mm, 1/3.2″, 1.4µm, AF |
|---|---|---|
| Video | 1080p@30fps |
| SUONO | Tipo suono | Vibrazione; MP3, suonerie WAV |
|---|---|---|
| Altoparlanti | Si, con altoparlanti stereo | |
| 3.5mm jack | No | |
| – 32-bit/384kHz audio – Riduzione rumore con mic dedicato |
| CONN | WLAN | Wi-Fi 802.11 a/b/g/n/ac, dual-band, DLNA, Wi-Fi Direct, hotspot |
|---|---|---|
| Bluetooth | 4.2, A2DP, aptX HD, LE | |
| GPS | Si, con A-GPS, GLONASS, BDS | |
| NFC | Si | |
| Porta Infrarossi | Si | |
| Radio | No | |
| USB | 3.1, Type-C 1.0 connettore reversibile; USB Host |
| FUNZIONI | Sensori | Impronta digitale, accelerometro, giroscopio, prossimità, barometro |
|---|---|---|
| Messaggi | SMS, MMS, Email, Push Email, IM | |
| Browser | HTML5 | |
| – Ricarica veloce 4.5V/5A (58% in 30 min) – DivX/XviD/MP4/H.265/WMV player – MP3/eAAC+/WMA/WAV/FLAC player – Document editor – Photo/video editor |
| BATTERIA | Li-Po 4000 mAh non rimovibile |
|---|
| VARIE | Colori | Midnight Blue, Titanium Gray, Mocha Brown, Pink Gold |
|---|---|---|
| Prezzo | Circa 400 EUR |