La maggior parte delle persone non ci pensa molto nell’utilizzare Google Foto per archiviare e condividere immagini e video personali, fino a quando qualcosa non va storto. In questo modo: Google sta avvisando alcuni utenti che i loro video potrebbero essere finiti accidentalmente nelle mani di qualcun altro.
Prima di allarmarvi, spieghiamo. Secondo un tweet di Jon Oberheide, che è stato vittima della violazione, si è svolto tra il 21 novembre 2019 e il 25 novembre 2019 e ha coinvolto Google Takeout, che consente di esportare una copia dei contenuti nel proprio account Google o utilizzarlo con un servizio di terze parti. Non è chiaro esattamente cosa sia andato storto, ma Google afferma che “alcuni video di Google Foto sono stati esportati in modo errato in archivi di utenti non correlati“. Google non ha avuto problemi sulle foto.
Google ha comunicato che il problema è stato identificato e risolto, quindi sembra essere correlato a un bug, non ad attività dannosa. Le e-mail vengono inviate a persone interessate dal problema, quindi se non ne ricevi una, i tuoi video sono al sicuro.
Ovviamente nessuno vuole che i video personali vengano inviati a estranei, questa violazione non è così grave come potrebbe sembrare. E’ durato solo cinque giorni ed era specificamente correlato all’esportazione di dati tramite Google Takeout, che la maggior parte delle persone probabilmente non conosce nemmeno. Quindi questa è una percentuale estremamente piccola di utenti.
Certo, sarebbe stato bello se Google avesse avvisato gli utenti quando è successo, piuttosto che due mesi dopo – e se sei uno degli utenti interessati – ma non dovresti preoccuparti e togliere tutte le tue foto dal servizio. Tuttavia, non è una cattiva idea cogliere l’occasione per controllare la tua libreria di foto o video altamente sensibili.
I conti economici di Alphabet non sono piaciuti agli economisti ed investitori. Il gruppo che controlla Google e della raccolta pubblicitaria digitale ha avuto utili operativi trimestrali in rialzo del 12,7% a 9,3 miliardi, meno dei 9,9 miliardi previsti. Gli utili netti sono saliti a 10,67 miliardi da 8,9. Il giro d’affari è rimasto a sua volta lontano dalle aspettative, 46,1 miliardi, in aumento del 17,3%, contro i 46,9 miliardi anticipati. Gli utili operativi sono risultati inferiori ai pronostici per nove degli ultimi dieci trimestri.
“Sono particolarmente soddisfatto per i nostri costanti progressi”, ha osservato il Ceo di Alphabet e Google, Sundar Pichai, indicando in particolare il giro d’affari di YouTube che è cresciuto dagli 8,1 miliardi di dollari del 2017 a 11,5 miliardi nel 2018 fino a superare i 15 miliardi di dollari nel 2019. Positiva anche performance di Google Cloud che nel 2019 ha registrato ricavi pari a oltre 9 miliardi di dollari, in rialzo del 53% sul 2018.
YouTube da sola ha fatturato 15,15 miliardi di dollari nel 2019, e vale il 10% di tutti gli incassi messi a segno da Google. Per la prima volta in quindici anni il colosso di Mountain View ha deciso di rendere noti i numeri relativi alla piattaforma video, che si conferma una delle punte di diamante del gruppo ormai interamente guidato da Sundar Pichai.
Le password complesse sono ovviamente fondamentali per la tua sicurezza. La sfida è creare password complesse che puoi effettivamente ricordare, senza cadere nelle cattive abitudini che possono danneggiarti, come riutilizzare la stessa password per più account. Ma quante password riesci a ricordare? Potresti avere facilmente 85 password per tutti i tuoi account, dal bancario allo streaming ai social media.
Le password deboli o l’uso eccessivo della stessa password possono avere gravi conseguenze se i dati sono compromessi, anche se tale password è sicura. Ad esempio, nel 2019 le aziende hanno segnalato 5.183 violazioni dei dati che hanno rivelato informazioni personali come credenziali di accesso e indirizzi di casa che qualcuno potrebbe utilizzare per frodare o rubare la tua identità. E dal 2017, gli hacker hanno pubblicato 555 milioni di password rubate sul Web oscuro che i criminali possono utilizzare per violare i tuoi account.
La sicurezza della password potrebbe non impedire completamente l’esposizione dei dati, ma queste migliori pratiche possono aiutare a minimizzare il rischio. Ecco come creare e gestire le migliori password, come scoprire se vengono rubate e un suggerimento essenziale per rendere i tuoi account ancora più sicuri.
Utilizzare un gestore di password per tenere traccia delle password
Le password complesse sono più lunghe di otto caratteri, difficili da indovinare e contengono una varietà di caratteri, numeri e simboli speciali. I migliori possono essere difficili da ricordare, soprattutto se si utilizza un accesso distinto per ogni sito (che è consigliato). Qui entra in gioco la gestione delle password.
Un gestore di password di fiducia come 1Password o LastPass può creare e archiviare password complesse e lunghe per te. Funzionano su desktop e telefono.
Il piccolo avvertimento è che dovrai ancora memorizzare una singola password principale che sblocca tutte le altre password. Quindi rendilo il più forte possibile (e vedi sotto per suggerimenti più specifici al riguardo).
Browser come Google Chrome e Firefox di Mozilla sono dotati anche di gestori di password, ma il metodo di protezione delle password che memorizzano non è dei migliori, è preferibile utilizzare un’app dedicata.
I gestori di password con i loro contenuti sono, ovviamente, obiettivi ovvi per gli hacker. E i gestori di password non sono perfetti. Lo scorso settembre LastPass ha corretto un difetto che avrebbe potuto esporre le credenziali di un cliente.
Scrivere le tue credenziali di accesso. Veramente?
Questa raccomandazione va contro tutto ciò che ci è stato detto sulla protezione di noi stessi online. Ma i gestori di password non sono per tutti e alcuni dei maggiori esperti di sicurezza, come la Electronic Frontier Foundation, suggeriscono che conservare le informazioni di accesso su un foglio di carta fisico o su un taccuino sia un modo fattibile per tenere traccia delle credenziali.
E stiamo parlando di un vero documento vecchio stile, non di un documento elettronico come un file Word o un foglio di calcolo di Google, perché se qualcuno accede al tuo computer o agli account online, può anche ottenere l’accesso a quel file di password elettronica.
Certo, questo è utile nel caso l’attacco avvenga online, come in virus, come una intrusione esterna. C’è però un pericolo nella scrittura fisica, amici e “partner”, o colleghi invidiosi. Se qualcuno sapesse che le tue password sono su un blocchetto o un foglio, sarebbe facilissimo per chiunque prenderlo. E’ quindi un qualcosa di sconsigliato.
Scopri se le tue password sono state rubate
Non è sempre possibile impedire il furto delle password, attraverso una violazione dei dati o un hack dannoso. Ma puoi verificare in qualsiasi momento la presenza di suggerimenti che potrebbero compromettere i tuoi account.
Mozilla Firefox Monitor e Google Password Checkup possono mostrarti quali dei tuoi indirizzi e-mail e password sono stati compromessi in una violazione dei dati in modo da poter agire. Have I Been Pwned può anche mostrarti se le tue e-mail e password sono state rubate.
Evita parole e combinazioni comuni nella tua password
L’obiettivo è creare una password che qualcun altro non conosce o non sarà in grado di indovinare facilmente. Stai lontano da parole comuni come “password”, frasi come “parola chiave” e sequenze di caratteri prevedibili come “qwerty” o “buongiorno”.
Evita anche di usare il tuo nome, soprannome, il nome del tuo animale domestico, il tuo compleanno o anniversario, il nome della tua strada o qualsiasi cosa associata a te che qualcuno potrebbe scoprire dai social media o da una conversazione sentita con uno sconosciuto su un aereo o al bar.
Le password più lunghe sono migliori: 8 caratteri è un punto di partenza
8 caratteri sono un ottimo punto di partenza quando si crea una password complessa, ma le combinazioni più lunghe sono migliori. La Electronic Frontier Foundation e l’esperto di sicurezza Brian Curbs, tra molti altri, consigliano di utilizzare una passphrase composta da tre o quattro parole casuali per una maggiore sicurezza. Una passphrase più lunga composta da parole non connesse può essere difficile da ricordare, tuttavia, è per questo che dovresti prendere in considerazione l’uso di un gestore di password.
Non riciclare le tue password
Vale la pena ripetere che riutilizzare le password su account diversi è un’idea terribile. Se qualcuno scopre la tua password riutilizzata per un account, ha la chiave per ogni altro account per cui usi quella password.
Lo stesso vale per la modifica di una password di root che cambia con l’aggiunta di un prefisso o suffisso. Ad esempio, PasswordOne, PasswordTwo (entrambi sono dannosi per diversi motivi). Scegliendo una password univoca per ciascun account, se anche la tua password fosse scoperta non potrebbero usarla per accedere a tutto il resto.
Non è necessario reimpostare periodicamente la password
Per anni, cambiare le password ogni 60 o 90 giorni è stata una pratica accettata come sicura, perché, secondo il pensiero, era il tempo impiegato per decifrare una password.
Ma Microsoft ora consiglia che, a meno che non si sospetti che le password siano state esposte, non è necessario modificarle periodicamente. La ragione? Molti di noi, costretti a cambiare le nostre password ogni pochi mesi, cadono in cattive abitudini nel creare password facili da ricordare o scriverle su foglietti adesivi e metterle sui nostri monitor.
Usa l’autenticazione a due fattori (2FA) ma cerca di evitare i codici dei messaggi di testo
Se i ladri rubano la tua password, puoi comunque impedire loro di accedere al tuo account con l’ autenticazione a due fattori (chiamata anche verifica in due passaggi o 2FA), una protezione di sicurezza che richiede di inserire una seconda informazione che solo tu hai (di solito un codice una tantum) prima che l’app o il servizio ti conceda accesso.
In questo modo, anche se un attacker scopre le tue password, senza il tuo dispositivo di controllo (come il tuo telefono) e il codice di verifica che conferma che sei davvero tu, non sarà in grado di accedere al tuo account.
Mentre è comune e conveniente ricevere questi codici in un messaggio di testo sul tuo cellulare o in una chiamata al tuo telefono fisso, è abbastanza semplice per un intruso rubare il tuo numero di telefono attraverso la frode di scambio SIM e quindi intercettare il tuo codice di verifica.
Un modo molto più sicuro per ricevere i codici di verifica è quello di generare e recuperarli tu stesso utilizzando un’app di autenticazione come Authy , Google Authenticator o Microsoft Authenticator. E una volta configurato, puoi scegliere di registrare il tuo dispositivo o browser in modo da non dover continuare a verificarlo ogni volta che accedi.
Quando si tratta di sicurezza delle password, essere proattivi è la migliore protezione. Ciò include sapere se la tua e-mail e le password si trovano sul dark web. E se scopri che i tuoi dati sono stati rubati agisci immediatamente con esperti o pratiche di sicurezza.
Negli anni ’90, quandosi parlava di sicurezza informatica a chiunque, uno sguardo vitreo appariva sulla faccia. La sicurezza, come disciplina dell’IT, era un po’ noiosa e difficile da capire.
Poi è entrata in campo Internet e tutti siamo stati cooptati nel campo informatico in un modo o nell’altro. Le truffe sono però aumentate e sono ora così onnipresenti che molti paesi hanno attivato i propri servizi governativi nel tentativo di educare i cittadini. Negli Stati Uniti, ad esempio, la Federal Trade Commission (FTC) ha un sito Scam Alert dedicato a portare le ultime truffe nel forum pubblico. Un altro esempio è l’Australia, con il suo sito Scamwatch.
Anche così, l'”utente” in genere non vuole pensare alla sicurezza. Internet può essere ovunque, ma la sicurezza è ancora noiosa. Fino a quando succede qualcosa di antipatico, allora la gente si siede e ricerca la sicurezza.
Tuttavia, come azienda, dobbiamo avere il nostro personale e altri collaboratori a guardia delle minacce informatiche. Dobbiamo assicurarci che la sicurezza esca dall’ombra e sia presente in modo da ridurre le possibilità che la nostra azienda sia vittima di un attacco informatico. In questo, come in molte aree tecnologiche, unisce l’interazione utente con la sicurezza.
Elementi di UX negli strumenti di sicurezza informatica
Per fare un’analogia con un’altra area tecnologica: se si progettasse un sito Web commerciale nel modo in cui sono progettati molti strumenti o processi di sicurezza, si perderebbero i clienti. Gli strumenti di cibersicurezza, anche quelli pensati per i consumatori, possono spesso essere complicati da comprendere e configurare. Alcuni casi d’uso ci danno un’idea di come UX può influire sulle scelte di sicurezza.
Le credenziali di accesso e autenticazione
È ormai noto che l’utilizzo di un secondo fattore (2FA) come un codice di autenticazione insieme a un nome utente e una password è più sicuro. Tuttavia, l’utilizzo da parte dei consumatori di 2FA non è ottimale. Google, ad esempio, ha un tasso di assorbimento di 2FA solo nel 10% circa degli utenti.
Tuttavia, un sondaggio ha scoperto che la consapevolezza di 2FA sta migliorando e il codice di testo SMS è il metodo più popolare. Negli Stati Uniti, oltre la metà degli utenti utilizza 2FA per alcuni account. La protezione di account più sensibili o di valore ha il maggior numero di utenti 2FA, ad esempio per l’accesso sicuro al conto bancario.
Uno dei problemi con 2FA per i consumatori è che si tratta di un passaggio in più, un ostacolo. Aggiunge tempo a un’interazione e clic extra. Il problema è che se qualcosa è difficile da fare, spesso non verrà fatta dagli utenti.
L’uso di un’app mobile, come Google Authenticator, potrebbe avere una sicurezza migliore rispetto a un messaggio SMS (che potrebbe essere intercettato) ma ha un utilizzo inferiore. Questo perché la UX di un’app comporta clic aggiuntivi per aprire l’app, scorrere fino al codice e così via.
Uno dei migliori approcci di UX nell’uso dei codici di testo SMS per 2FA è usarli in un percorso utente interamente mobile. Fai clic per accedere a un account su un dispositivo mobile, il codice SMS viene inviato, l’interfaccia ti consente di fare clic sul codice, che viene inserito automaticamente nel campo di accesso all’account, e sei dentro. La UX è semplice, senza soluzione di continuità e riduce l’attrito; è un ottimo UX, quindi è un UX sicuro.
Quando una buona sicurezza peggiora la UX
Un esempio di quando la buona sicurezza va a male a causa della scarsa UX è nel prodotto Pretty Good Privacy (PGP). PGP fornisce la crittografia end-to-end delle comunicazioni e-mail. Viene utilizzato in un client di posta elettronica, ProtonMail.
PGP è stato originariamente sviluppato come prodotto autonomo, ma non è mai decollato al di fuori della comunità tecnologica. Molti si sono chiesti perché un prodotto di sicurezza così efficace non sia mai diventato mainstream. Una delle teorie più popolari è che l’interfaccia utente era mal progettata, essendo un’interfaccia utente altamente tecnica e che richiedeva una comprensione della “gestione delle chiavi”: dovevi sapere come condividere, gestire e mantenere le chiavi di crittografia.
In altre parole, la UX di PGP era tale da aggiungere ostacoli al suo utilizzo. Lo usavano solo quelli che erano pronti a saltare quegli ostacoli.
Il caso dei gestori di password
Anche i gestori password sono usati male. Risolvono il problema del ricordarsi tante password diverse e aggiungono un livello di sicurezza agli account che dispongono solo di un’autenticazione a fattore singolo (alcuni offrono maggiore sicurezza rispetto ad altri). Tuttavia, un rapporto Pew Research ha rilevato che solo circa il 12% degli utenti utilizza un gestore di password.
Uno dei problemi con i gestori di password è che possono essere difficili da installare e gestire per l’utente medio. È più facile scrivere una password.
Carnegie Mellon Cylab ha esaminato il motivo per cui i gestori di password non sono stati utilizzati. Le risposte includevano:
Il riutilizzo delle password ha reso più semplice il solo ricordare le password
Annotarli / salvarli in un telefono è stato più facile
Dare il controllo delle loro password al software era di per sé una preoccupazione
In tutti gli esempi precedenti, la scarsa UX ha portato a pratiche di sicurezza scadenti. UX è fondamentale per una buona esperienza utente di sicurezza e per far funzionare la sicurezza.
Una buona UX garantisce una buona sicurezza nei processi
Una grande esperienza utente è l’obiettivo. Per creare una UX eccezionale, è necessario iniziare con alcune considerazioni di progettazione:
Un team diversificato: disporre di un team che includa persone diverse può aiutare a progettare un’ottima UX. Ad esempio, hai pensato agli utenti disabili nel tuo prodotto o processo?
Progetta per i tuoi utenti, non per te stesso: quando progetti un prodotto o un processo di sicurezza, pensa al tuo pubblico. Quali sono probabilmente i dati demografici? La lingua è adatta all’utente? L’interfaccia è accessibile?
Provalo nel mondo reale: prova con utenti reali che rappresentano il gruppo demografico usando il tuo processo o prodotto. Esegui test A / B per ottenere la migliore UX che puoi
Preparati a cambiare : continua i test, continua a perfezionare
Utilizzabile e sicuro: l’equilibrio tra usabilità e sicurezza è una costante del settore, ma è necessario trovare un mezzo felice. Se aggiungi ostacoli UX, la sicurezza sarà inficiata. Si finisce con una situazione in cui si potrebbe anche peggiorare la sicurezza – l’esempio in cui l’utente sceglie di riutilizzare le password per ricordarle, piuttosto che un gestore di password, è un caso emblematico
Sappiamo quasi tutto della nuova gamma Galaxy S20 di Samsung, ed è una nuova serie che pare molto entusiasmante. Ma Samsung sta anche per lanciare uno smartphone Galaxy molto più “nuovo” che potrebbe lanciare una nuova moda.
Con un (apparente) grave errore, Samsung ha reso noti i render ufficiali per il suo nuovissimo smartphone pieghevole insieme alle specifiche chiave. Chiamato Galaxy Z Flip, sembra destinato a essere uno degli smartphone più ambiziosi del 2020 e sfoggia un design che potrebbe portare gli smartphone pieghevoli nel grande mercato.
Il display
Scelto dall’acclamato Evan Blass (aka @evleaks ) e dal sempre eccellente Roland Quandt di WinFuture, vediamo per la prima volta immagini ad alta risoluzione del Galaxy Z Flip che mostra il suo design a conchiglia, cornici sottili e display allungato che può essere ridotto in un dispositivo veramente tascabile che protegge completamente lo schermo in caso di caduta. Questa modifica delle dimensioni è molto importante con il telefono che misura 167,9 x 73,6 x 6,9-7,2 mm quando è aperto e solo 87,4 x 73,6 x 15,4-17,3 mm chiuso. Per fare un confronto, un iPhone SE è lungo 123,8 mm.
Come tale, il display pieghevole è il fulcro, che misura 6,7 pollici quando è aperto con un rapporto 22: 9 (più alto di un telefono Galaxy standard che è 19,9) e una risoluzione nativa di 2636 x 1080. Ha una fotocamera centrale come il Galaxy S20 e una cover “Ultra Thin Glass” sul display progettata per renderla più resistente del pannello interamente in plastica del Galaxy Fold. C’è anche un piccolo display esterno da 1,06 pollici (300 x 116 pixel) in modo da poter vedere le notifiche quando il telefono è piegato.
Le telecamere
In termini di telecamere, Quandt rivela sia le fotocamere posteriori (12MP, f1.8 primarie + 12MP, f2.2 grandangolari) sia quelle frontali (10MP, f2.4). C’è anche una batteria da 3.300 mAh, ricarica wireless e USB-C. Pesa 183 g, rendendolo 42 g più leggero di un iPhone 11 Pro Max.
Lati negativi? Internamente, Samsung ha equipaggiato il Galaxy Z Flip con un chipset Snapdragon 855+ (non SD865 all’interno dell’S20 ) e c’è uno slot microSD o 5G. Detto questo, il telefono avrà 8 GB di RAM e 256 GB di memoria nativa come standard, il che significa che dovrebbero esserci velocità e spazio di archiviazione sufficienti per la maggior parte degli utenti.
Il prezzo
E la caratteristica killer: il prezzo. Con il Galaxy Fold in vendita a 2.000 dollari, Huawei dice che il suo Mate X sarà superiore a 2.500, il Galaxy Z Flip avrà un costo di 1.300 euro. Sì, vivere all’avanguardia non è economico ma Motorola addebiterà lo stesso prezzo per il suo RAZR pieghevole in arrivo e che ha specifiche significativamente inferiori.
Sì, le specifiche Galaxy S20 sono ancora più elevate e il prezzo di partenza sarà più basso.
Il malware è complesso e creato per confondere chi lo analizza. Molti utenti di computer pensano che il malware sia solo un’altra parola per “virus” quando un virus è in realtà un tipo di malware. Oltre ai virus, il malware include ogni sorta di codice dannoso e indesiderato, inclusi spyware, adware, trojan e worm.
È sempre necessario il rapido rilevamento e l’estrazione di un malware dai sistemi informatici, ma il malware non lo renderà facile. Il malware è malizioso e scivoloso, usando trucchi come offuscamento, codifica e crittografia cerca di eludere il rilevamento.
Offuscamento del malware
Comprendere l’offuscamento è più facile che pronunciarlo. L’offuscamento del malware rende i dati illeggibili. Quasi ogni malware utilizza questa tecnica.
I dati incomprensibili di solito contengono parole importanti, chiamate “stringhe”. Alcune stringhe contengono identificatori come il nome del programmatore del malware o l’URL da cui viene estratto il codice malevolo. La maggior parte dei malware offusca le stringhe di codice che nascondono le istruzioni che dicono alla macchina infetta cosa fare e quando farlo.
L’offuscamento nasconde i dati del malware così bene che gli analizzatori di codice spesso non riescono a capire come è stato istruito il malware. Solo quando viene eseguito il programma viene rivelato il vero codice.
Semplici tecniche di offuscamento del malware
Vengono comunemente utilizzate semplici tecniche di offuscamento del malware come OR esclusivo (XOR), Base64, ROT13 e codepacking. Queste tecniche sono facili da implementare. L’offuscamento può essere semplice come il testo interposto o un’ulteriore inserimento di codice inutile all’interno di una stringa. Anche gli occhi allenati spesso non riescono a cogliere il codice offuscato.
Il malware imita i casi d’uso quotidiani fino a quando non viene eseguito. Al momento dell’esecuzione, viene rivelato il codice dannoso, che si diffonde rapidamente attraverso il sistema.
Tecniche avanzate di offuscamento del malware
L’offuscamento del malware di livello successivo è attivo ed evasivo. Tecniche avanzate di malware, come la consapevolezza dell’ambiente in cui il codice gira, la confusione degli strumenti automatizzati, l’evasione basata sui tempi e l’offuscamento dei dati interni, consentono al malware di nascondersi all’interno degli ambienti operativi e non essere tracciati dai software antivirus moderni.
Alcuni malware prosperano facendo clic al posto degli utenti su link appositi per scaricare file malware o aprire pagine Web dannose, mentre altri intercettano il traffico e iniettano malware, ottenendo un impatto vasto e rapido.
Utilizzo di cifrari e schemi di codifica per offuscare il malware
Obiettivo del gioco è nascondersi e confondere. Puzzle malware con semplici cifre e schemi di codifica. Rendere il malware difficile da rilevare e decodificare ritardi nell’analisi e nella correzione, poiché il codice dannoso lavora continuamente dietro le quinte.
Codifica malware
Base64 viene spesso utilizzato per codificare malware. Sembra un linguaggio militare ma in realtà è un comune schema di codifica da binario a testo. È stato creato per codificare e decodificare al servizio dello standard Internet MIME (Multipurpose Internet Mail Extensions) che formatta le e-mail per la trasmissione.
Lo scopo essenziale di Base64 è standardizzare il codice. I programmatori ne approfittano iniettando stringhe di caratteri false che imitano lo standard Base64. Il codice sembra standard e funziona normalmente fino a quando non viene decodificato.
Decodifica del malware
È inoltre necessaria una strategia offensiva per combattere la codifica, la crittografia e l’offuscamento del malware. Il software utilizzato per decodificare il malware ha lo scopo di rivelarlo in modo logico e diretto prima dell’esecuzione del malware.
Dopo l’esecuzione, il malware si diffonde e il codice diventa illeggibile. Le stringhe di testo problematiche vengono prima isolate, quindi vengono utilizzate tecniche di ricerca e sostituzione per eliminare il codice dannoso. Una volta rimosso, puoi vedere un’immagine più chiara del codice pulito.
Crittografia malware
In senso tradizionale, la crittografia del malware è il processo di codifica delle informazioni in modo che solo le parti autorizzate possano accedere ai dati in un formato leggibile.
Quando la crittografia malware viene utilizzata per scopi dannosi, si chiama ransomware. Il ransomware tiene in ostaggio i file usando la crittografia. Quando viene ricevuto il pagamento del riscatto, i file vengono decifrati e l’utente recupera l’accesso. I creatori di malware di oggi in genere chiedono il pagamento sotto forma di criptovaluta.
Il malware infetta spesso i sistemi attraverso tecniche di phishing o altre tattiche che utilizza la posta elettronica, ponendosi come e-mail legittima, convincendo un utente a fare clic su un collegamento o a scaricare un file.
Ingegneria inversa e algoritmi crittografici comuni
Gli ingegneri cercano di arrivare al codice partendo dal malware, lavorano all’indietro dall’infezione, utilizzano strumenti di disassemblaggio per rivelare le modifiche ai file che si verificano quando un malware attacca. La crittografia viene spesso utilizzata da programmatori malintenzionati per impedire il disassemblaggio e quindi impedire il reverse engineering.
È utile se gli ingegneri comprendono i comuni algoritmi crittografici utilizzati per creare codice crittografato simmetricamente. Se la crittografia del malware è stata creata utilizzando un algoritmo crittografico comune, il codice può essere decrittografato e il reverse engineering può continuare. Se la crittografia è asimmetrica, tuttavia, l’algoritmo non offrirà la chiave per la decrittazione.
La crittografia asimmetrica implica la generazione di due chiavi completamente diverse; tuttavia condividono una relazione. Una chiave (la chiave pubblica) viene utilizzata per crittografare i dati in testo cifrato, mentre il suo compagno (la chiave privata) viene utilizzato per decodificare il testo cifrato nel testo normale originale. Si chiama asimmetrico perché la chiave pubblica, sebbene sia stata utilizzata per crittografare, non può essere utilizzata per decrittografare. La chiave privata è necessaria per decrittografare.
Questa ovviamente è solo una panoramica di primo approccio al grande sistema di analisi dei malware. E’ un mondo affascinante. Con grandi e continue innovazioni.
Come gestiremo l’intelligenza artificiale? Come fare in modo che macchine dall’intelligenza sempre più spiccata riescano a rimanere agli ordini degli esseri umani e raggiungano gli obiettivi utili all’umanità intera? e come manterremo il controllo su delle macchine sempre più intuitive ed intelligenti?
Stuart Russell
Una delle principali voci sul tema è quella di Stuart Russell, professore di Computer Science all’Università della California e dirigente del centro per l’intelligenza artificiale presso Barkley.
“Per comprendere l’evoluzione della intelligenza artificiale – spiega Russell – è necessario innanzitutto fare un po’ di storia. Nella metà degli anni ’80, l’idea che l’intelligenza artificiale potesse entrare nel mondo reale era già stata sdoganata da diversi film e libri di fantascienza.
I ricercatori erano impegnati a costruire dei sistemi che erano essenzialmente delle suite di regole per affrontare determinati tipi di problemi: si trattava di affrontare diagnosi mediche, configurare un supercomputer, o gestire macchine complesse. In quell’epoca vennero sviluppati migliaia di sistemi, ma la maggior parte di questi non funzionava al 100% nel mondo reale.
Questo perché più si aggiungono regole ad un sistema informatico e più questo inizia a sbagliare. Partì quindi un processo di miglioramento graduale: innanzitutto si accumularono tanti problemi da risolvere, alchè si svilupparono teorie via via sempre migliori e si perfezionarono le conoscenze che si avevano.
Lo sviluppo dell’intelligenza artificiale non fu omogeneo: ci furono periodi in cui le conoscenze si propagarono più velocemente e altri periodi durante i quali lo sviluppo parve entrare in crisi. Un passo di svolta fu il cosiddetto “Deep Learning”. Si tratta di una metodologia per cui i sistemi sono in grado di imparare dall’analisi dei dati e dal confronto delle informazioni che emergono dopo un errore.
Questo fu fondamentale per sviluppare tecnologie come il riconoscimento vocale, la capacità di distinguere le immagini o la traduzione simultanea.
Il miglioramento delle abilità
A partire dal 2012, gli scienziati hanno osservato un rapido miglioramento delle abilità di questi sistemi nel riconoscere gli oggetti e le immagini e svolgere altri compiti intelligenti. Ed è quello che sta succedendo anche adesso, cosa che sta attirando una enorme quantità di investimenti, una serie di startup e lo sviluppo di una vasta gamma di applicazioni come le auto a guida automatica.
L’impatto delle tecnologie di intelligenza artificiale e già oggi significativo: l’esempio principale sono le auto che si guidano da sole. E’ una novità che ha dato luogo ad una industria rivoluzionaria del valore di miliardi di dollari. Nelle previsioni degli scienziati, ognuno sarà più sicuro camminando per strada, la mobilità cittadina migliorerà in diversi stati del mondo e ridurremo gli ingorghi stradali.
Questo dovrebbe permetterci, nella migliore delle ipotesi, di ridisegnare le nostre città, molte delle quali avranno delle zone di parcheggio più ampie e tratti meno congestionati
Ma le tecnologie di intelligenza artificiale coinvolgono anche aspetti che sono meno visibili: non molto tempo fa i motori di ricerca non esistevano nemmeno. Ora invece gli algoritmi intelligenti scandagliano costantemente il web per individuare nuovo materiale e integrarlo all’interno di un modello per svolgere funzioni che ci sono utili.
Quando noi eseguiamo una ricerca su internet, il sistema prova a restituire una risposta fornendoci dati ai quali potremmo essere maggiormente interessati. I motori di ricerca rappresentano già un elaborazione estremamente complessa e una applicazione di intelligenza artificiale decisamente avanzata, già adesso utilizzata da miliardi di persone ogni giorno.
I sistemi comprenderanno le nostre intenzioni
Nel prossimo decennio dovremmo assistere a un reale progresso nella comprensione dei linguaggi, tale che i sistemi non saranno solamente capaci di riconoscere che cosa stiamo dicendo al nostro telefono o al nostro home-assistant. I sistemi saranno in grado di comprendere le nostre intenzioni, di sostenere delle conversazioni con noi e di imparare le nostre abitudini e i dettagli della nostra vita, in modo da diventare degli assistenti realmente utili nella quotidianità.
Probabilmente queste intelligenze artificiali saranno paragonabili agli assistenti personali che oggi accompagnano gli amministratori delegati o i politici. Solo che anziché costare decine di migliaia di dollari all’anno, saranno vendute per 99 centesimi. Questo significherà certamente che l’intelligenza artificiale diventerà parte delle nostre vite. E non solo interagiremo ogni giorno con queste strumentazioni, ma esse diventeranno essenziali per gestire la nostra routine quotidiana.
Anche l’educazione di questi sistemi è un’altra vasta area di interesse. Al momento attuale, l’intelligenza artificiale è in grado, sotto forma di risposta a domande che gli poniamo, di fornirci dati relativi a qualcosa che ha già imparato. Ma questo cambierà: avremo a disposizione dei sistemi di autoapprendimento estremamente sofisticati, che permetteranno ai computer di fornire delle risposte, anche se non hanno in memoria i dati.
Saranno così in grado di concepire, come la mente umana, delle frasi e dei concetti che non hanno avuto modo di apprendere in precedenza.
Se guardiamo ancora più lontano, inizieremo ad avere un’idea più dettagliata di quello che sarà l’intelligenza artificiale nei prossimi decenni. I sistemi non saranno capaci solamente di risolvere uno specifico problema o seguire un determinato compito per il quale sono stati programmati, ma saranno in grado di collaborare con noi ed eseguire l’intera gamma di azioni che un essere umano può pensare.
La strada per arrivare ad uno scenario del genere comunque è ancora lunga è difficile. Predire quanto tempo ci vorrà per arrivare a dei sistemi così sofisticati è molto difficile, in quanto non si tratta solamente di una questione di quantità o potenza di calcolo. Non si tratta solamente di creare delle macchine che possano gestire più dati, in quanto macchine più potenti possono paradossalmente rispondere con maggiore imprecisione.
Come i pappagalli
Abbiamo bisogno di sviluppare invece dei percorsi concettuali per migliorare la precisione dei sistemi di intelligenza artificiale. Per fare un esempio immediatamente comprensibile: i computer sono simili a dei pappagalli, che riconoscono una serie di istruzioni legate alla nostra comunicazione e sanno già come rispondere, ma non sono in grado di leggere un libro, capirne dei concetti e rispondere a seconda delle nostre domande.
Abbiamo quindi bisogno di superare dei determinati limiti e raggiungere una reale comprensione del linguaggio da parte delle macchine per realizzare delle organizzazioni complesse nel mondo reale e avere dentro di sé una serie di processi per la scoperta di nuove informazioni.
Le macchine non sono ancora in grado di fare tutto questo, e per sviluppare tale capacità sono necessari dei percorsi concettuali che vanno sviluppati. Ritengo comunque che entro i prossimi 10 anni avremo un evoluzione significativa: molti ricercatori di intelligenza artificiale amano dire che è come se fossimo nel Medioevo, in attesa di qualche cosa che ridisegnerà le capacità dell’ intelligenza artificiale globale.
Lo sviluppo dell’intelligenza artificiale può essere paragonato a un sistema evolutivo dove gli scienziati creano degli ambienti simulati dove le creature possono evolvere. Queste partono con un codice genetico simulato, al quale possono essere aggiunte delle funzioni che permettono a queste creature di riprodursi. Gli scienziati di intelligenza artificiale vogliono fare realmente questa serie di test con prototipi di uomini e animali, per vedere quanto saranno in grado di spingersi e quanto velocemente le macchine potranno evolversi.
Hanno bisogno di creare ambienti in cui i piccoli robot possono crescere, calcolare quanto velocemente si possono muovere e quali sono le applicazioni che gli consentono di migliorare le prestazioni più rapidamente possibile. Ci troveremo certamente di fronte a robot capaci di evolvere molto presto ma con dei punti deboli importanti oppure altre situazioni in cui la crescita sara molto più lenta ma più stabile.
Tuttavia, quando queste macchine raggiungeranno il mondo reale, ci saranno degli enormi effetti collaterali.
Per esempio: tutti gli algoritmi che abbiamo sviluppato per i social media sono pensati per gli esseri umani. Tutti gli algoritmi che utilizziamo per la pubblicità online sono strutturati per gestire i click umani, il modo con cui il nostro cervello scansiona una pagina web così come altre metriche per la monetizzazione dei video di YouTube, non sono concepite per i robot.
Gli attuali algoritmi su cui si basano i social media sono molto semplici e non prendono minimamente in considerazione la possibilità di interagire con un robot. Per questo ritengo che i prodotti robotici, una volta arrivati sul mercato, conosceranno dei primi grandi fallimenti, almeno sino a che non saremo capaci di adattare il mondo reale alla presenza di queste intelligenze artificiali.
Fino a dove potrebbero spingersi le intelligenze artificiali?
Probabilmente le macchine saranno in grado di capire e afferrare l’esistenza di un obiettivo da raggiungere, comprendere quando questo non è stato raggiunto completamente, eseguire alcuni tentativi e nel caso in cui questi siano sbagliati, cercare di comunicare agli esseri umani di che cosa hanno bisogno per completare la missione.
Uno dei problemi principali è che le macchine non sanno esattamente quale sia l’obiettivo. Se un robot deve afferrare una mela, siamo portati a credere che la macchina sappia esattamente che l’obiettivo è prendere nella sua mano meccanica tale oggetto.
Ma questo è un errore; non sempre, anzi quasi mai, le macchine hanno la esatta consapevolezza del mondo fisico attorno a loro e di cosa noi vogliamo. Potrebbe trattarsi di una conoscenza parziale, per cui le macchine sono costrette ad eseguire dei calcoli probabilistici per cercare di capire qual è l’obiettivo.
L’esempio più calzante è quando cerchiamo di indovinare le previsioni del tempo. Possiamo capire cosa probabilmente ci riserverà il domani, ma non riusciamo ad avere la certezza della temperatura e delle condizioni atmosferiche che si verificheranno fra 24 ore. La stessa cosa accade ai computer quando cercano di capire quello che noi vogliamo da loro.
E finché le macchine non hanno l’esatta consapevolezza degli obiettivi che noi desideriamo, potrebbero assumere dei comportamenti diversi da quelli previsti. Questo significa che almeno in una fase iniziale dovremmo realizzare dei robot in grado di chiedere il permesso per svolgere i compiti, in modo da prevenire dei comportamenti inappropriati ed evitare azioni catastrofiche.
In gergo tecnico usiamo dire che i robot ragionano esattamente come nella teoria dei giochi.
La teoria dei giochi studia le metodologie per prendere delle decisioni corrette laddove c’è più di una modalità di arrivare all’obiettivo. Si tratta di una teoria che viene utilizzata per le tattiche militari, per i mercati finanziari e tutti i tipi di problemi che affliggono il mondo reale. Per le macchine sarà lo stesso: i robot potranno raggiungere l’obiettivo in più modi diversi e per capire il metodo migliore dovranno collaborare con l’essere umano. Proveranno certamente ad aiutare l’uomo senza chiedergli informazioni, ma alla fine sarà il suo “padrone” ad avere il controllo della situazione e ad avere ben chiaro in mente quale sia il reale obiettivo finale.
Per questo le macchine dovranno necessariamente risolvere in continuazione dei piccoli enigmi per cercare di agganciare il comportamento preferito dagli esseri umani.
Un’app di messaggistica molto popolare è stata definita come un modo sicuro per chattare con amici e familiari ma in realtà sarebbe uno strumento di spionaggio utilizzato dagli Emirati Arabi Uniti per tenere traccia delle attività di coloro che la scaricano, secondo quanto riportato dal New York Times. L’app, che ha debuttato solo pochi mesi fa, è stata scaricata milioni di volte in tutto il mondo.
L’app è uno strumento di sorveglianza di massa, secondo The Times, in grado di monitorare ogni conversazione, movimento, relazione, appuntamento, suono e immagine dei suoi utenti. La maggior parte degli utenti dell’app è negli Emirati, ma recentemente è cresciuta in popolarità negli Stati Uniti.
Gi esperti di sicurezza
Analisi e interviste con esperti di sicurezza informatica suggeriscono che la compagnia dietro ToTok, Breej Holding, è una facciata buona per nascondere DarkMatter, una società di cyberintelligence e hacking con sede ad Abu Dhabi che impiega funzionari dell’intelligence degli Emirati, ex dipendenti della National Security Agency ed ex agenti dell’intelligence militare israeliana.
L’app è stata recentemente rimossa dagli app store di Apple e Google, ma è ancora funzionante fino a quando gli utenti non la eliminano dal proprio dispositivo.
I rappresentanti di Apple e Google non hanno immediatamente risposto alle richieste di commento. Breej Holding non è stata raggiunta per un commento.
Le accuse relative a ToTok provengono da accresciute preoccupazioni per i governi che usano segretamente app per raccogliere informazioni sui loro obiettivi. TikTok, un’app cinese incredibilmente popolare nota per i suoi stravaganti video di 15 secondi, è stata accusata di aver raccolto illegalmente e segretamente grandi quantità di dati utente identificabili personalmente e di inviarli in Cina.
Una proposta di class-action è stata depositata contro TikTok all’inizio di questo mese, e il governo degli Stati Uniti è alla ricerca di app con potenziali rischi per la sicurezza. Le preoccupazioni relative alla sicurezza informatica hanno spinto la Marina degli Stati Uniti a vietare l’app da dispositivi mobili emessi dal governo.
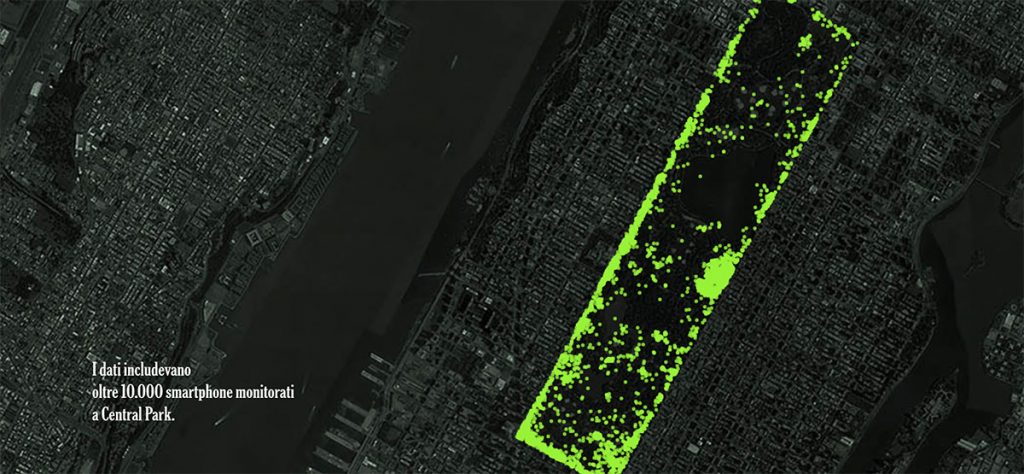
Ogni minuto di ogni giorno, ovunque sul pianeta, dozzine di aziende – in gran parte non regolamentate, poco controllate – registrano i movimenti di decine di milioni di persone con i telefoni cellulari e archiviano le informazioni in file di dati giganteschi. Il Times Privacy Project ha ottenuto uno di questi file, di gran lunga il più grande e il più sensibile mai visto dai giornalisti. Detiene oltre 50 miliardi di ping di localizzazione dai telefoni di oltre 12 milioni di americani mentre si muovevano attraverso diverse città importanti, tra cui Washington, New York, San Francisco e Los Angeles.
Ogni informazione in questo file rappresenta l’ubicazione precisa di un singolo smartphone per un periodo di diversi mesi nel 2016 e nel 2017. I dati sono stati forniti a Times Opinion da fonti che hanno chiesto di rimanere anonime perché non erano autorizzati a condividerlo e potevano affrontare gravi sanzioni per averlo fatto. Le fonti delle informazioni affermano di essersi allarmate per come potrebbero essere violate e di voler urgentemente informare il pubblico e i legislatori.
Dopo aver trascorso mesi a vagliare i dati, rintracciare i movimenti delle persone in tutto il paese e parlare con dozzine di società di dati, tecnici, avvocati e accademici che studiano questo campo, proviamo lo stesso senso di allarme. Nelle città coperte il file di dati, traccia le persone di quasi tutti i quartieri, sia che vivano in case mobili ad Alessandria, in Virginia, sia in torri di lusso a Manhattan.
Una ricerca ha rivelato più di una dozzina di persone che visitavano il Playboy Mansion, alcune durante la notte. Senza troppi sforzi abbiamo individuato i visitatori nelle tenute di Johnny Depp, Tiger Woods e Arnold Schwarzenegger, collegando i proprietari dei dispositivi alle abitazioni a tempo indeterminato.
Se vivevi in una delle città il set di dati copre e usa app che condividono la tua posizione, dalle app meteo alle app di notizie locali ai risparmiatori di coupon.
Se riesci a vedere tutto, potresti non utilizzare mai più il telefono allo stesso modo.
I dati raccolti da aziende sconosciute
I dati esaminati da Times Opinion non provenivano da una società di telecomunicazioni o di tecnologia gigante, né provenivano da un’operazione di sorveglianza governativa. Proviene da una società di dati sulla posizione, una delle dozzine che raccolgono silenziosamente movimenti precisi utilizzando il software inserito nelle app di telefonia mobile. Probabilmente non hai mai sentito parlare della maggior parte delle aziende, eppure a chiunque abbia accesso a questi dati, la tua vita è un libro aperto. Possono vedere i luoghi in cui vai in ogni momento della giornata, persone con cui ti incontri o con cui passi la notte, dove preghi, sia che tu visiti una clinica per metadone, uno studio di psichiatra o una sala massaggi.
Il Times e altre organizzazioni giornalistiche hanno riferito sul monitoraggio degli smartphone in passato. Ma mai con un set di dati così grande. Tuttavia, questo file rappresenta solo una piccola parte di ciò che viene raccolto e venduto ogni giorno dall’industria del localizzazione – sorveglianza così onnipresente nella nostra vita digitale che ora sembra impossibile da evitare per chiunque.
Sorveglianza continua
Non ci vuole molta immaginazione per evocare i poteri che una sorveglianza sempre attiva può fornire ad un regime autoritario come quello cinese.
All’interno della democrazia rappresentativa stessa dell’America, i cittadini sarebbero senz’altro indignati se il governo avesse tentato di imporre che ogni persona sopra i 12 anni avesse un dispositivo di localizzazione che rivelasse la propria posizione 24 ore al giorno.
Eppure, nel decennio dalla creazione dell’App Store di Apple, gli americani, app per app, hanno acconsentito proprio a un tale sistema gestito da società private.
Ora, alla fine del decennio, decine di milioni di americani, tra cui molti bambini, si ritrovano a portare spie nelle loro tasche durante il giorno e a lasciarli accanto ai loro letti di notte – anche se le società che controllano i loro dati sono molto meno responsabili rispetto al governo.
“La seduzione di questi prodotti di consumo è così potente che ci rende ciechi alla possibilità che ci sia un altro modo per ottenere i benefici della tecnologia senza l’invasione della privacy. Ma c’è ”, ha affermato William Staples, direttore fondatore del Surveillance Studies Research Center dell’Università del Kansas.
“Tutte le aziende che raccolgono queste informazioni sulla posizione fungono da ciò che ho chiamato Tiny Brothers, utilizzando una varietà di raccolta di dati per impegnarsi nella sorveglianza quotidiana.“
Oggi è perfettamente legale raccogliere e vendere tutte queste informazioni. Negli Stati Uniti, come nella maggior parte del mondo, nessuna legge federale limita quello che è diventato un vasto e redditizio commercio di tracciamento umano.
Solo le politiche aziendali interne e la decenza dei singoli dipendenti impediscono a coloro che hanno accesso ai dati di, per esempio, inseguire un coniuge o vendere il pendolarismo serale di un ufficiale dei servizi segreti a un potere straniero ostile.
Le aziende affermano che i dati sono condivisi solo con partner controllati. Anche se queste società stanno agendo con il codice morale più solido che si possa immaginare, alla fine non esiste alcun modo infallibile per proteggere i dati da eventuali furti.
Più semplicemente, su una scala più piccola ma non meno preoccupante, ci sono spesso poche protezioni per impedire a un singolo analista con accesso a tali dati di rintracciare un ex-amante o una vittima di abusi.
La mappa delle persone
Le aziende che raccolgono tutte queste informazioni sui tuoi movimenti giustificano la loro attività sulla base di tre affermazioni: le persone acconsentono a essere rintracciate, i dati sono anonimi e i dati sono sicuri.
Nessuna di queste affermazioni regge, in base al file che abbiamo ottenuto e alla nostra revisione delle pratiche aziendali.
Sì, i dati sulla posizione contengono miliardi di punti dati senza informazioni identificabili come nomi o indirizzi e-mail. Ma è un gioco da ragazzi collegare nomi reali ai punti che appaiono sulle mappe.
Ecco come appare.
Nella maggior parte dei casi, accertare la posizione di una casa e di un ufficio era sufficiente per identificare una persona. Considera il tuo tragitto giornaliero: quale altro smartphone viaggerebbe direttamente tra casa e ufficio ogni giorno?
Descrivere i dati sulla posizione come anonimi è “un’affermazione completamente falsa” che è stata smentita in numerosi studi, ci ha detto Paul Ohm, professore di legge e ricercatore di privacy presso il Georgetown University Law Center. “Le informazioni di geolocalizzazione longitudinale veramente precise sono assolutamente impossibili da anonimizzare.”
“DNA”, ha aggiunto, “è probabilmente l’unica cosa che è più difficile da anonimizzare di informazioni precise sulla geolocalizzazione”.
Tuttavia, le aziende continuano a dichiarare che i dati sono anonimi. Nei materiali di marketing e nelle conferenze di settore, l’anonimato è un importante punto di forza – chiave per attenuare le preoccupazioni su tale monitoraggio invasivo.
Per valutare le affermazioni delle società, abbiamo rivolto gran parte della nostra attenzione all’identificazione delle persone in posizioni di potere. Con l’aiuto di informazioni pubblicamente disponibili, come gli indirizzi di casa, abbiamo facilmente identificato e quindi monitorato decine di notabili. Abbiamo seguito i funzionari militari con autorizzazioni di sicurezza mentre tornavano a casa di notte. Abbiamo rintracciato le forze dell’ordine mentre portavano i loro figli a scuola. Abbiamo visto avvocati di alto livello (e i loro ospiti) mentre viaggiavano da jet privati a proprietà per le vacanze. Non abbiamo nominato nessuna delle persone che abbiamo identificato senza il loro permesso.
Osservare i punti muoversi su una mappa a volte rivelava accenni di matrimoni vacillanti, prove di tossicodipendenza, registrazioni di visite a strutture psicologiche.
Collegare un ping anonimo a un vero essere umano nel tempo e nel luogo potrebbe sembrare come leggere il diario di qualcun altro.
Trasmettiamo costantemente dati, ad esempio, navigando in Internet o effettuando acquisti con carta di credito. Ma i dati sulla posizione sono diversi. Le nostre posizioni precise vengono utilizzate al momento per un annuncio o una notifica mirati, ma poi riutilizzate indefinitamente per fini molto più redditizi, come legare i tuoi acquisti a pubblicità di cartelloni pubblicitari che hai superato in autostrada. Molte app che utilizzano la tua posizione, come i servizi meteorologici, funzionano perfettamente senza la tua posizione precisa, ma la raccolta della tua posizione alimenta un’attività redditizia secondaria di analisi, licenze e trasferimento di tali informazioni a terzi.
Dati alla mercè di tutti
Un certo numero di aziende vende i dati dettagliati. Gli acquirenti sono in genere broker di dati e società pubblicitarie. Ma alcuni di essi hanno poco a che fare con la pubblicità dei consumatori, tra cui istituti finanziari, società di analisi geospaziale e società di investimento immobiliare in grado di elaborare e analizzare così grandi quantità di informazioni. Potrebbero pagare più di 1 milione di dollari per una tranche di dati, secondo un ex dipendente della società di dati sulla posizione che ha accettato di parlare in modo anonimo.
I dati sulla posizione vengono anche raccolti e condivisi insieme a un ID pubblicità mobile, un identificatore apparentemente anonimo di circa 30 cifre che consente agli inserzionisti e ad altre aziende di collegare attività tra le app. L’ID è anche usato per combinare percorsi di localizzazione con altre informazioni come il tuo nome, indirizzo di casa, e-mail, numero di telefono o anche un identificatore collegato alla tua rete Wi-Fi.
I dati possono cambiare di mano in tempo quasi reale, così velocemente che la tua posizione può essere trasferita dallo smartphone ai server dell’app ed esportata a terzi in millisecondi. Ecco come, ad esempio, potresti vedere un annuncio per una nuova auto un po ‘di tempo dopo aver attraversato una concessionaria.
Tali dati possono quindi essere rivenduti, copiati, piratati e abusati.
Questo articolo è una traduzione libera e parziale della inchiesta del New York Times
Gli attacker hanno avuto accesso a oltre 7,9 miliardi di record di consumatori finora quest’anno, con gli esperti che prevedono che entro la fine dell’anno saranno esposti oltre 8,5 miliardi di account.
La maggior parte degli oltre 5.000 hack di dati quest’anno consisteva solo in pochi milioni di account. Eppure c’erano alcuni mega hack che hanno coinvolto centinaia di milioni.
Il Centro risorse per il furto di identità ha fornito una classifica delle maggiori violazioni dei dati scoperte nel 2019, in base al numero di account compromessi. Diverse aziende, come 7-Eleven , WhatsApp e Fortnite , hanno segnalato difetti di sicurezza che avrebbero potuto esporre milioni di dati dei clienti, ma la portata dei dati a cui si è avuto accesso non è stata segnalata.
Ecco uno sguardo alle maggiori violazioni dei dati del 2019, nonché suggerimenti su come proteggere i tuoi account.
5. Quest Diagnostics
Numero di record compromessi: 11,9 milioni
All’inizio di giugno, la società di test di laboratorio Quest Diagnostics ha annunciato di aver riscontrato una violazione dei dati che colpisce il suo fornitore di fatturazione, l’American Medical Collection Agency. La violazione ha rivelato le informazioni mediche, finanziarie e personali di circa 11,9 milioni di clienti nel corso di otto mesi. Ciò includeva numeri di carta di credito, informazioni sul conto bancario, informazioni mediche e numeri di previdenza sociale.
L’hacking dell’AMCA ha interessato anche LabCorp, che ha anche rivelato dati personali e finanziari su 7,7 milioni di consumatori. Poche settimane dopo l’annuncio delle violazioni, AMCA ha presentato istanza di fallimento, citando “enormi spese” che la società ha accumulato notificando ai clienti la violazione e il fatto che molti dei suoi maggiori clienti sono decaduti. LabCorp e Quest Diagnostics hanno entrambi abbandonato AMCA dopo aver appreso della violazione, nonché Conduent e CareCentrix.
4. Houzz
Numero di record compromessi: 48,9 milioni
Il sito web di design per la casa Houzz ha dato il via all’anno informando i clienti che gli hacker avevano avuto accesso a nomi utente e password crittografate, nonché a informazioni sul profilo pubblicamente visibili. Le FAQ della società sulla violazione erano vaghe, ma ITRC riportava 48.881.308 account interessati. Nessuna informazione finanziaria è stata presa, ha detto Houzz, aggiungendo che è venuta a conoscenza della violazione nel dicembre 2018.
3. Capital One
Numero di record compromessi: 100 milioni
Capital One ha annunciato una massiccia violazione dei dati a fine luglio, riferendo che un hacker ha avuto accesso alle informazioni di oltre 100 milioni di americani e 6 milioni di canadesi che hanno richiesto carte di credito dal 2005.
L’azienda ha comunicato che i file rubati contenevano informazioni personali degli utenti compresi nomi, indirizzi, codici zip, indirizzi email, numeri di telefono e date di nascita. Numeri bancari e numeri di previdenza sociale sono stati compromessi per circa 140,0000 i clienti degli Stati Uniti di carte di credito e circa 80.000 clienti assicurati con carta di credito che avevano i loro numeri di conto bancario collegato a cui si accede.
A differenza di altri principali hack, i dati a cui si accede durante la violazione di Capital One includevano dati sensibili, come i numeri di previdenza sociale.
2. Dubsmash
Numero di record compromessi: 161,5 milioni
A febbraio, l’app di messaggistica video Dubsmash ha annunciato che gli hacker hanno acquisito quasi 162 milioni di nomi di titolari di account, indirizzi e-mail e password con hash. Le password con hash sono crittografate, quindi devono essere decrittate prima di poter essere utilizzate.
La violazione si è effettivamente verificata a dicembre 2018, ma i ladri informatici hanno pubblicato che i dati erano in vendita sul web da febbraio. Faceva parte di un dump di dati che includeva oltre 600 milioni di account da 16 siti Web compromessi.
1. Zynga
Numero di record compromessi: 218 milioni
Il produttore di giochi per cellulare Zynga ha annunciato a ottobre che un hacker aveva avuto accesso alle informazioni di accesso dell’account il 12 settembre per i clienti che giocavano ai popolari giochi “Disegna qualcosa” e “Parole con gli amici”.
Oltre alle credenziali di accesso, l’hacker ha avuto accesso a nomi utente, indirizzi e-mail, ID di accesso, alcuni ID di Facebook, alcuni numeri di telefono e ID account Zynga di circa 218 milioni di clienti che hanno installato versioni di giochi iOS e Android prima del settembre. 2, 2019.
Come proteggere i tuoi dati
Mentre i furti sopra elencati sono i maggiori verificatisi, ci sono state una serie di minori violazioni dei dati che hanno fatto poca notizia di importanti aziende come DoorDash, Evite e Georgia Tech, nonché agenzie governative come la Federal Emergency Management Agency (FEMA).
I consumatori devono essere vigili sulle attività sospette indipendentemente dal fatto che siano state colpite da una recente violazione dei dati. “Il meglio che un individuo può fare è tenere d’occhio i truffatori che li contattano”, afferma l’analista indipendente per la sicurezza informatica Graham Cluley.
Oltre ad essere vigili, ecco alcuni altri passaggi che puoi adottare per proteggerti.
Verifica se i tuoi account sono coinvolti
Anche se non sei stato coinvolto nelle cinque maggiori violazioni dei dati, vale la pena verificare se le tue informazioni sono state compromesse in altri hack.
Il consumatore medio è stato coinvolto in sei violazioni dei dati, afferma Larry Ponemon, fondatore del think tank sulla protezione e sicurezza dei dati Ponemon Institute. “La maggior parte delle persone non si rende conto di essere diventata vittima di una violazione dei dati”.
"Utilizziamo i cookie per personalizzare contenuti ed annunci, per fornire funzionalità dei social media e per analizzare il nostro traffico. Condividiamo inoltre informazioni sul modo in cui utilizza il nostro sito con i nostri partner che si occupano di analisi dei dati web, pubblicità e social media, i quali potrebbero combinarle con altre informazioni che ha fornito loro o che hanno raccolto dal suo utilizzo dei loro servizi.
Cliccando su “Accetta tutti”, acconsenti all'uso di tutti i cookie. Cliccando su “Rifiuta”, continui la navigazione senza i cookie ad eccezione di quelli tecnici. Per maggiori informazioni o per personalizzare le tue preferenze, clicca su “Gestisci preferenze”."
Questo sito web utilizza i cookie.
I siti web utilizzano i cookie per migliorare le funzionalità e personalizzare la tua esperienza. Puoi gestire le tue preferenze, ma tieni presente che bloccare alcuni tipi di cookie potrebbe avere un impatto sulle prestazioni del sito e sui servizi offerti.
Essential cookies enable basic functions and are necessary for the proper function of the website.
Name
Description
Duration
Cookie Preferences
This cookie is used to store the user's cookie consent preferences.
30 days
These cookies are used for managing login functionality on this website.
Name
Description
Duration
wordpress_test_cookie
Used to determine if cookies are enabled.
Session
wordpress_sec
Used to track the user across multiple sessions.
15 days
wordpress_logged_in
Used to store logged-in users.
Persistent
Statistics cookies collect information anonymously. This information helps us understand how visitors use our website.
Google Analytics is a powerful tool that tracks and analyzes website traffic for informed marketing decisions.
Used to monitor number of Google Analytics server requests when using Google Tag Manager
1 minute
_ga_
ID used to identify users
2 years
_gid
ID used to identify users for 24 hours after last activity
24 hours
_gali
Used by Google Analytics to determine which links on a page are being clicked
30 seconds
_ga
ID used to identify users
2 years
__utmx
Used to determine whether a user is included in an A / B or Multivariate test.
18 months
__utmv
Contains custom information set by the web developer via the _setCustomVar method in Google Analytics. This cookie is updated every time new data is sent to the Google Analytics server.
2 years after last activity
__utmz
Contains information about the traffic source or campaign that directed user to the website. The cookie is set when the GA.js javascript is loaded and updated when data is sent to the Google Anaytics server
6 months after last activity
__utmc
Used only with old Urchin versions of Google Analytics and not with GA.js. Was used to distinguish between new sessions and visits at the end of a session.
End of session (browser)
__utmb
Used to distinguish new sessions and visits. This cookie is set when the GA.js javascript library is loaded and there is no existing __utmb cookie. The cookie is updated every time data is sent to the Google Analytics server.
30 minutes after last activity
__utmt
Used to monitor number of Google Analytics server requests
10 minutes
__utma
ID used to identify users and sessions
2 years after last activity
_gac_
Contains information related to marketing campaigns of the user. These are shared with Google AdWords / Google Ads when the Google Ads and Google Analytics accounts are linked together.
90 days
Marketing cookies are used to follow visitors to websites. The intention is to show ads that are relevant and engaging to the individual user.
X Pixel enables businesses to track user interactions and optimize ad performance on the X platform effectively.
Our Website uses X buttons to allow our visitors to follow our promotional X feeds, and sometimes embed feeds on our Website.
2 years
personalization_id
Unique value with which users can be identified by X. Collected information is used to be personalize X services, including X trends, stories, ads and suggestions.
2 years
guest_id
This cookie is set by X to identify and track the website visitor. Registers if a users is signed in the X platform and collects information about ad preferences.
2 years
Per maggiori informazioni, consulta la nostra https://www.alground.com/origin/privacy-e-cookie/